Representatividade – o que é esse processo? erro de cobertura
O conceito de representação é comum em otchetnostyakh estatística e na preparação de discursos e relatórios. Talvez sem ela é difícil imaginar qualquer tipo de apresentação de informações em exposição.
Representatividade – o que é?

Representatividade reflete como os objetos ou partes selecionadas correspondem ao conteúdo e significado da população de dados de onde foram selecionados.
outras definições
O conceito de representação pode ser expandido em diferentes contextos. Mas sua representação significado – é recursos de conformidade e propriedades de unidades selecionadas da população em geral que refletem com precisão as características gerais de todo o banco de dados como um todo. 
Também informações representativas é definida como a capacidade de enviar uma amostra conjunto de dados de parâmetros e propriedades que são importantes do ponto de vista da investigação em curso.
amostra representativa
O princípio da amostragem é importante na escolha a mais precisa e exibindo as propriedades de um conjunto de dados. Ele usa uma variedade de métodos, que permitem obter resultados precisos e uma visão geral da população em geral, utilizando apenas materiais seleccionados, que descrevem a qualidade dos dados.
Assim, não há necessidade de aprender todo o material, e basta considerar uma representação seletiva. O que é isso? Esta é uma amostra de dados individuais, a fim de ter uma idéia sobre a massa total de informações. 
Eles são, dependendo do método de distinto como probabilidade e não-probabilidade. Probabilidade – uma amostra do que é feito através do cálculo dos dados mais importantes e interessantes, que são mais representantes da população em geral. Isto é uma escolha deliberada ou uma amostra aleatória, no entanto, justificada pelo seu conteúdo.
Probabilística – é uma forma de uma amostra aleatória de no princípio habitual de lotaria. Neste caso, a opinião da pessoa que faz essa seleção. Ele usa desenhar apenas cega.
amostragem probabilística
amostragem probabilística também pode ser dividido em vários tipos:
- Um dos princípios mais simples e claras – uma amostra de conveniência. Por exemplo, este método é frequentemente utilizado na realização de pesquisas sociais. Neste caso, os entrevistados não são selecionados a partir da multidão em quaisquer características particulares, e informações produzidas nas primeiras 50 pessoas que participaram na mesma.
- amostragem deliberada diferem em que eles têm uma série de requisitos e condições para a seleção, mas ainda dependem de coincidência, não perseguir a meta de alcançar boas estatísticas.
- A amostra com base em quotas – esta é uma outra variação de amostra on-probabilística, que é frequentemente utilizado para a análise de grandes conjuntos de dados. Para ela, usou uma variedade de condições e normas. objetos selecionados para combiná-los. Esse é o exemplo do inquérito social sugere que serão entrevistados 100 pessoas, mas apenas a opinião de um número de pessoas que vão ao encontro das exigências especificadas serão tidas em conta na elaboração de relatórios estatísticos.

amostragem probabilística
Para probabilidade de amostragem estimado número de opções que os objetos na amostra irá atender, entre eles uma série de maneiras de ser eleitos precisamente os fatos e dados que serão apresentados como a representatividade dos dados da amostra. Estes métodos computar os dados necessários podem ser:
- amostragem aleatória simples. Encontra-se no facto de entre o segmento seleccionado completamente seleccionado aleatoriamente quantidade necessária de lotaria de dados que vai ser amostra representativa.
- amostragem sistemática e aleatória faz com que seja possível criar um sistema de cálculo os dados necessários com base em um segmento aleatório. Assim, se o primeiro número aleatório, que indica o número ordinal de dados seleccionados a partir da população geral, é 5, em seguida, os dados subsequentes a ser seleccionado pode ser, por exemplo, 15, 25, 35 e assim por diante. Este exemplo explica claramente que mesmo uma selecção pode basear-se em cálculos sistemáticos de dados brutos necessários.
clientes de amostra
amostra significativa – um método que consiste em considerar cada segmento individual, e com base em sua avaliação de conjunto compilado de refletir as características e propriedades do banco de dados compartilhado. Assim marcado maior quantidade de dados que correspondem a um requisitos de amostragem representativa. É possível selecionar facilmente um número de opções que não serão incluídos no número total, sem perder a qualidade dos dados selecionados que representam a população total. Desta maneira, a representatividade dos resultados do estudo.
O tamanho da amostra
Não última questão que deve ser abordada – é o tamanho da amostra para a representatividade da população. tamanho da amostra nem sempre dependem do número de fontes na população. No entanto, a representatividade da amostra depende de quantos segmentos devem ser dividido eventualmente resultado. Os mais segmentos, mais dados entra amostra produtivo. Se os resultados exigem um termo genérico e não requer especificidades, então, respectivamente, a amostra torna-se menor, porque, sem entrar em detalhes, a informação é apresentada mais superficial, o que significa que a sua interpretação é compartilhada.

O conceito de erros de representatividade
margem de erro – a diferenças específicas entre as características dos dados da população e da amostra. Durante qualquer amostragem é absolutamente impossível obter dados precisos, como na população do estudo completo e amostra representou apenas parte das informações e opções, enquanto um estudo mais detalhado é possível apenas no estudo de todo o conjunto. Assim, inevitavelmente alguns erros e erros.
tipos de erros
Distinguir alguns erros que ocorrem na preparação de uma amostra representativa:
- Sistemático.
- Aleatória.
- Intencional.
- Não intencional.
- Padrão.
- Limite.
A base para o aparecimento de erros aleatórios pode ser natureza descontínua do estudo da população total. Normalmente, o erro aleatório de representatividade tem o tamanho pequeno e caráter.
erros sistemáticos ocorrem entre os dados em violação das regras de seleção da população em geral. 
O erro médio – a diferença entre os valores médios da amostra e o conjunto básico. Ela não depende do número de unidades da amostra. Ele é inversamente proporcional ao volume da amostra. Em seguida, quanto maior o volume, menor o valor da média de erro.
limite de erro – é a maior diferença possível entre o valor médio vai fazer a amostra ea população total. Este erro é caracterizado como os erros mais prováveis sob condições dadas de sua ocorrência.
erros intencionais e não intencionais de representatividade
Dados compensar erros são intencionais e não intencionais.
Em seguida, as razões para o surgimento de erro intencional é uma abordagem para a seleção dos dados pelo método de determinação das tendências. erros não intencionais ocorrer na fase de preparação de observação da amostra, formação de uma amostra representativa. Para evitar tais erros, você deve criar uma boa base para a amostragem, lista as unidades de seleção de componentes. Ele deve ser totalmente coerente com os objectivos da amostragem para ser exato, cobrindo todos os aspectos do estudo.
Validade, confiabilidade, representatividade. erros de cálculo

Cálculo de erro de amostra (mm) a média aritmética (M) significa.
Desvio padrão: o tamanho da amostra (> 30).
A margem de erro (Mp) e um valor relativo tamanho da amostra (P) (n> 30).
No caso em que é necessário estudar o agregado, em que a quantidade da amostra é pequeno e é menos do que 30 unidades, então o número de casos será inferior a uma unidade.
valor de erro diretamente proporcional ao tamanho da amostra. informações representativas e o cálculo do grau de possibilidade de elaborar uma previsão exata reflete um certo erros de limite de valor. 
sistemas representativos
Não só no processo de avaliação de apresentação da informação usando uma amostra representativa, mas também a pessoa que recebe a informação utiliza sistemas representacionais. Assim, o cérebro processa certa quantidade de informações para criar uma amostra representativa de todo o fluxo de informações a fim de avaliar de forma eficiente e rapidamente os dados fornecidos e compreender o assunto. Para responder à pergunta: "representatividade – que este" – pura e simplesmente a escala da consciência humana. Para fazer isso, o cérebro usa tudo subordinado ao sentidos, dependendo do que tipo de informação deve ser separado da corrente geral. Assim, é feita a distinção entre: 
- sistema de representação visual onde os órgãos são utilizados percepção visual do olho. As pessoas muitas vezes usam um sistema semelhante, chamado visuais. Com este sistema, uma pessoa processa as informações na forma de imagens.
- sistema representacional auditivo. O corpo principal, que é usado – este é um rumor. As informações fornecidas na forma de arquivos de som ou discurso, ela é processada pelo sistema. As pessoas estão mais receptivos à informação sobre a audiência, chamado audialami.
- sistema cinestésico representativo é um fluxo de processamento de informação através da detecção com os canais olfactivas e tácteis.

- sistema representativo digital é utilizado, juntamente com o outro como um meio de obter informação a partir do exterior. Esta percepção subjetiva e interpretação lógica dos dados.

Então representatividade – o que é? Seleção simples do conjunto ou procedimento integrante no processamento de informações? Podemos dizer que a representatividade determina em grande parte a nossa percepção de fluxos de dados, ajudando a isolar-lo o mais atraente e significativa.

Latest posts

Os sintomas da varicela em crianças: uma coceira desagradável e bolhas feias

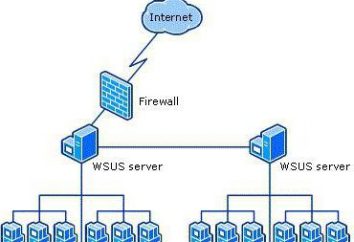
Windows Server Update Services (WSUS): configuração. WSUS offline Atualização







